I was looking for an introduction like “Due to the Corona crisis, ...”, as everybody does these days. Unfortunately, that won't work with the subject I'm going to talk about, namely, command line (CLI) applications, which I've used and liked in the pre-SARS-CoV-2 world just as much as now. I'm convinced since ages that the CLI is, to state it with the words of Luke, “the most intuitive, most natural and easiest to grasp type of user interface we have invented so far”.
But regardless of what I and others believe or not, lots of things are simply best done on the command line. There's a catch, of course: that statement is only true if and only if we are equipped with the right tools. An ancient /bin/sh without tab completion and history search and no access to my toolbox is nothing but a nightmare. Correctly configured, however, nothing beats the CLI in terms of speed and economy.
In the following, I'll provide a brief overview of the command line applications I'm regularly using for everyday duties such as server administration and file management, as well as a few more enjoyable activities. Two of my earlier posts have a certain overlap with the present one, but a different focus. My list is of course by no means exhaustive: you can find many more interesting tools and gadgets, ranging from the useful to the bizarre (try ternimal). Excellent starting points are the curated lists provided by Adam and Marcel. In addition, Igor (the guy behind wttr) compiled a list of web services available via the command line.
Shell
Work on the command line starts with the shell. The default in most distributions is the bash, and in a few the zsh. Both require extensive configuration to offer all features I'd like to see, and not all distributions provide such a custom setup (meaning, you got to do it). In contrast, fish is very well configured out-of-the-box regardless of the distribution. For the typical bash one-liner copied from the interwebs, I usually follow this advice.
Terminal
If we are not at the console, we need a terminal emulator. I'm primarily using Tilix or, when resources are scarce, Guake and Terminator, but there are plenty of other choices.
Remote Shell
A lot of my everyday duties involve connecting to a remote server. Wherever possible, I do that by using a combination of mosh and tmux, the benefits of which have been described, for example, by Filippo and Brian. For example, I'd use
mosh pdes-net.org --tmux new-session -s default
for connecting to and starting a new tmux session with the name 'default' on this server. I can detach with Ctrl+A-D and attach anytime again (also from an entirely different network) with
mosh pdes-net.org --tmux a
Note that mosh requires some open UDP ports that may require configuration of the firewall (for which I'm utilizing ufw, so it's as easy as 'ufw allow <port>/udp').
Navigation and file management
Everybody with a certain sense of order tends to get pretty long path names, which are a nuisance to type regardless of tab completion. That's basically why file managers were invented! But there's a faster way: autojump. Instead of typing the path, you could just jump to it:
cobra at deepgreen in ~
↪ j pra20_3
/home/cobra/ownCloud/MyStuff/projects/publications/uwe/pra20_1-3/pra20_3
cobra at deepgreen in ~/o/M/p/p/u/p/pra20_3
↪ j portfolio
/home/cobra/Documents/aur/portfolio
cobra at deepgreen in ~/D/a/portfolio
↪ j pdes
/home/cobra/ownCloud/MyStuff/Documents/pdes-net.org
cobra at deepgreen in ~/o/M/D/pdes-net.org
(blog) ↪
There are several tools similar to autojump, some more powerful, but in contrast to these, it's also officially available for Debian. And I'm used to it. ☺
On systems with an SSD, I like to use broot, which is neither yet another autojumper, nor a full-blown file manager, but something in between. It's also nice as a tool to get information on file dates and sizes.
As an actual file manager, I much prefer nnn, although I always also install ranger as well as the good old mc. Don't underestimate the latter – it may look oldfashioned and outdated, but none of its more fashionable cousins allows, for example, remote sftp connections (although I usually simply use scp for copying files between remote locations). And there's another small but decisive difference between mc and nnn/ranger that may simplify file selection and renaming for most people (see the appendix to this post below).
Commands one googles sooner or later:
show/hide hidden files
nnn .
ranger zh
mc Alt+.
disk usage
broot :s
nnn td or ta
Editor and other utilities
There can only be one: vim. Well: neovim. But that's it. 😉 In both cases, I use vim-plug as a plugin manager to load nnn as file opener (there is also a ranger plugin) and optionally vimtex whenever it's appropriate (although vim is not my primary TeX editor – a subject to which I will return in a forthcoming post). And if you really, really can handle neither vim nor emacs: try micro, it's the better nano. 😉
I put all documents that are still being edited under local version control. For this very simple task, I prefer mercurial over git because of the former's humanly readable version numbers (I just find it more natural and less demanding to address a commit with a natural number than with a hash). For LaTeX documents, I use scm-latexdiff to create diffs out of previous version managed by mercurial. And finally, I backup all of my documents and data with borg and rsync (and in future, also with rclone) as described in detail in my previous post.
Whatever I'm working on, it surely involves quick check on numbers, some simple, some involved. A lot of these can be done by qalc, a very versatile general purpose calculator, which has replaced calc after I've discovered that qalculate! also has a CLI...
System and network administration
Very much up on my list for this tasks are two rather unexpected tools, namely, a mail client and a scheduler. In fact, I rely on mutt (“All mail clients suck. This one just sucks less.”) for reading the mails sent by cronie. Whether I'm interested in the status of my hourly backups on the desktop or in the results of daily security checks on a remote server, this combination of tools is truly indispensable for getting important system messages. In the same category are tools for receiving security news and advisories such as newsboat with the appropriate feeds (or arch-audit on Arch), and of course the security auditing tool lynis.
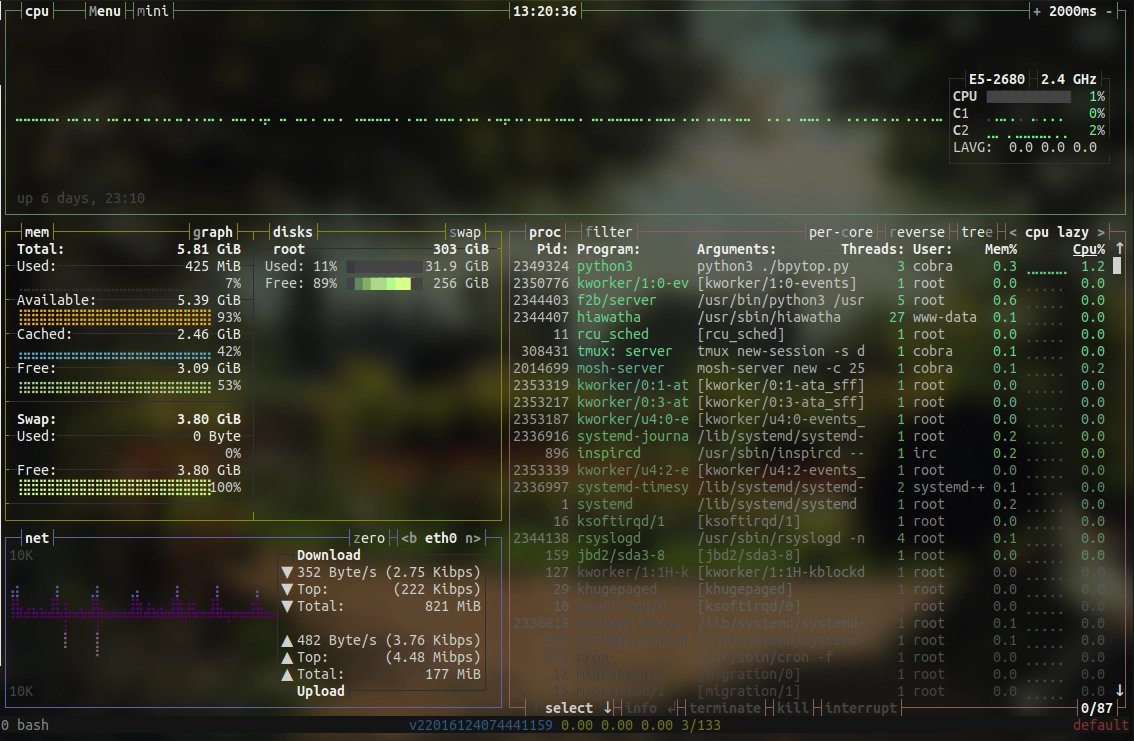
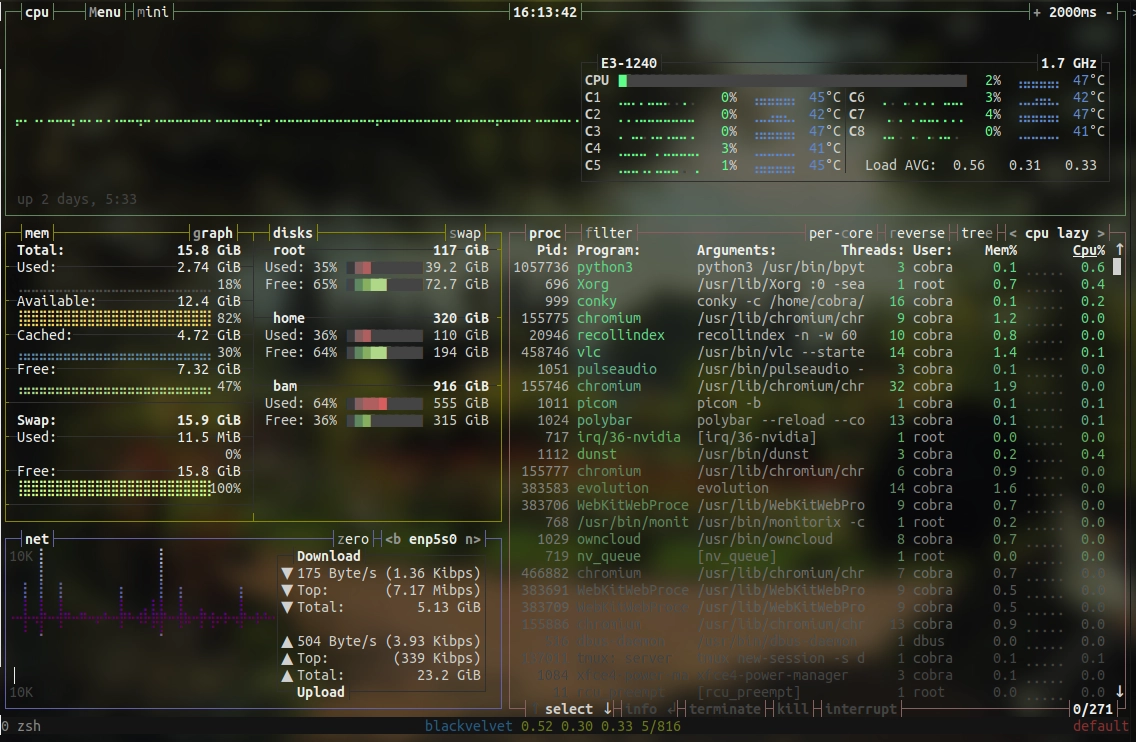
On servers, I often want to know who's logged in on a system and what this user is running. For this task, htop is the swiss army knife, offering an excellent overview of all system resources and activities and also the possibility to manage them. In particular, htop helps to find (and end) amok running applications consuming too many precious CPU cycles and RAM. Even more information offers bashtop, a veritable system monitor for the command line. Applications running wild while accessing the mass storage can be easily identified by iotop, and disk resources can be checked on a partition level by pydf and on a file level by ncdu (or by broot and nnn as mentioned above). For a more in-depth analysis of systems, tools such as dstat may become helpful, but my general experience has been rather that it either works, or is broken.
When I have problems with the snappiness of the interwebs (which has become very rare), I first turn to mtr which often helps to find the culprit (although there isn't anything one can do if one of the hops is overloaded and suffers from package loss). Several helpful tools exist if the problem seems to be rather on my side, such as dnstop, iftop, nethogs, iptraf, and more, but I think that these tools merit a separate post.
Spare time
All work and no play makes Cob a dull snake. I stream videos using mpv and youtube-dl, like everybody else. I used to listen music by moc, but I've switched to cmus a few year ago. Similarly, I've exchanged irssi for weechat to talk to friends. When I feel like getting some news from the world outside, I fire up newsboat for a list of feeds that I find amusing. And for a quick reality check, nothing works better than mop displaying a ticker of my stocks. The very compact ticker.sh lured me into creating a permanent ticker on my desktop via conky integration, but I found that it distracts me way too much.
Appendix: bulk rename
For sake of example, let's create 101 files with touch rha{0..100}.barber, and let's rename them so that the numbers are all three digits (like, 004 instead of 4, 023 instead of 23). We can do that the easy or the hard way.
mc gives us the choice, namely, between shell patterns (globs) and standard regular expressions (regexes). The file selection dialog (press +) has an option 'Using shell patterns'. Let's select that and perform our self-imposed task in three simple steps: first, we select all files with a single digit number (+ rha?.*), then rename them with F6 / rha?.* / rha0?.*, and then all with a two digit number with F6 / rha ??.* / rha0??.* Now, that was easy, wasn't it?
ranger doesn't understand globs, but allows the use of regexes with the :filter (zf) and :mark commands. The renaming is sourced out to the system wide editor, i.e., vim in my case, where we can use the substitute command (:s) and vim regexes (which are mostly identical to those used in, for example, sed and perl, but not identical). So let's start with selecting all files with a single digit number: :mark -rft rha[0-9].b, followed by :bulkrename. The selected files can be easily renamed in vim by :%s/\([0-9]\)/0\1/g, followed by ZZ to save the list and apply it. For the next bunch, we mark files again by :mark -rft rha[0-9]..b, :bulkrename, and repeat the above command in vim. Not quite as easy as with mc if one is not very familiar with regexes!
nnn is very similar to ranger in this regard. We can select files by the filter function employing either strings (/) or regexes (\). So we type \rha[0-9].b followed by r to open the selected files in vim. The rest is basically the same as for ranger.