C't 3/2013 contained three articles about password security and password cracking. Nothing earth-shattering, but a number of interesting insights.
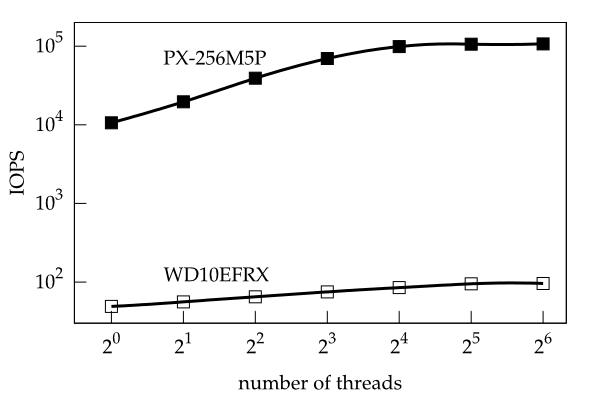
Advances on the password cracking scene are twofold. First, the hardware has advanced to a point where brute forcing an 8 digit password is a piece of cake if the hash algorithm used is sufficiently fast. For example, a single AMD 7970 is capable of processing about 16 billion NTML hashes per second, and a cluster of 25 of these cards has a reported throughput of 350 billion NTML hashes per second. An 8 digit password composed of small and capital letters as well as numbers spans a search space of 628. Our cluster would brute-force this password in 5 minutes (on average).
The second, and actually far more significant advance is due to password theft. In the past, many commercial sites miserably failed to protect the login data of their users. Often, the user passwords were stored in unsalted SHA1 databases which can be processed with speeds in excess of 100 billion hashes per second using GPU clusters such as referred to above. Many millions of passwords have been leaked that way:
# wc -l rockyou.dict
14344391
# wc -l hashkiller.dict
23685601
Dictionary attacks are now not only common, but actually constitute a major component of the toolbox for breaking passwords. Here are some examples of passwords whose hashes were looted from online databases and which were cracked subsequently:
--jmle94--*
jiujitsu131@
dlnxf780508
28075s10810
198561198561
viatebatefilmul
zhengbo645917
182953c99vk416
nielasus5752754sh
polU09*@l1nk3d1n
As you see, these passwords are not of the type one commonly expects to be easily broken.
Now, every one of us has (or should have) multiple passwords for shopping sites and other services on the interweb, with "multiple" meaning in this context several dozens or even several hundreds. Can we chose them such that they are immune to the attacks described above, and yet memorize them?
Lots of smart people have pondered over this problem. Four schemes have emerged which have recently become popular. The names I gave them are not necessarily the names of the inventors, but those of the people or media who popularized the respective scheme.
The oldest and most well-known scheme. To quote Bruce Schneier:
"My advice is to take a sentence and turn it into a password. Something like "This little piggy went to market" might become "tlpWENT2m". That nine-character password won't be in anyone's dictionary.
Well, perhaps not. But I bet that lots of people chose the same sentence, for example "Mary had a little lamb, whose fleece was white as snow", i.e., "mhallwfwwas" which are even 11 characters. And guess what: both of the dictionaries above actually contain this password. D'oh!
So you'd need an absolutely unique, private sentence. For each site you want to login to.
Let's try:
Amazon: "Die Frauen am unteren Amazonas haben durchschnittlich kleinere Brüste als gewohnt." dfauahdkbag
Google: "Die Zahl Googool ist groß, aber kleiner als 70!" dzgigaka7!
I don't know about you, but I don't think I could actually memorize the 72 sentences I'd need.
And if I need to write them down, as Bruce suggests ("If you can't remember your passwords, write them down and put the paper in your wallet. But just write the sentence - or better yet - a hint that will help you remember your sentence"), I can just as well use truly strong passwords (which I will discuss at the end of this entry).
Oh yes, this is the Steve Gibson who recommended Zonealarm all over the internet. But let's listen to what he wants to say.
Steve suggests to use a core term (such as dog) which is transformed to a password by padding, like "...dog.........". This idea is based on the simple fact that the length of a password is more important than the character space.
The idea has its merits. Yet, if I would apply this principle to all of my passwords, I certainly couldn't hope to memorize all if both the core term and the padding were varied. Let's try to change only the core:
Amazon: "...Amazonas......."
Google: ".......Googool..."
You could use "<<<<>>>>" instead, of course. Or any other padding. But if you think about it, the number of paddings is very limited. Steve's idea thus boils down to a simple password used in conjunction with a very predictable salt.
Bad idea.
Randall's web comic suggests that passphrases composed of a few common words are easier to remember and harder to crack than standard passwords consisting of letters, numbers, and special characters. That's once again a variation of the theme 'length over complication' which I have discussed in a previous entry. As an example, I gave 'HerrRasmussensAra', Randall has chosen 'correct horse battery staple'.
Randall estimates the entropy of his password in a very conservative fashion, assuming a dictionary size of only (244)1/4 = 211 = 2048. Let's use a real dictionary instead:
# wc -l /usr/share/dict/words
119095
That's the default dictionary for the xkcd password generator for Linux. The search space for a passphrase composed of 4 words from this dictionary is 11909544 = 67 bit large, essentially the same as for a password composed of 12 numbers and letters. Not larger?
Mind you: just combining two words won't do, regardless their length and obscurity. Using cudaHashcat-lite, it takes even my humble 650Ti (with roughly one third the single-precision throughput of the above mentioned 7970) less than one second to get your passphrase.
Does it help when trying to memorize the passwords?
Amazon: "Millionen Leser konifizieren Amazon".
Google: "Googlifizierung normalisiert Billionen Hornissen."
You see that you run into the same problem as with Schneier's scheme. 😞
Or Schmidt scheme, since it is always propagated by Jürgen Schmidt, the head of Heise Security. The idea is as simple as it is appealing: take a strong, random master password you can still easily remember, such as ":xT9/qwB". Combine that with a snippet derived from the domain name, such as "ad6" for amazon.de or "gc6" for google.com. Voilà, you got a strong password which is easily reconstructed for as many sites as you wish.
Is it? Schmidt emphasizes never to use the same password twice, but "gc6" may represent google.com as well as gibson.com. Using simply the domain names is much too obvious, and the reason why many passwords are broken easily. Should we use "goc6" and "gib6"? Several sites won't accept passwords that long anyway, nor passwords containing characters such as ":" and "/".
There goes the vision of a univeral master password. Schmidt further disillusions the reader by telling him not to use the full master password on sites he doesn't fully trust. The criteria for this trust, however, remain unclear, particularly because Schmidt explicitly states that users can't recognize which sites are trustworthy. He proposes further exceptions for sites he trusts even less (?), for which he's using passwords which are not entirely obvious but easy to crack.
And finally, he proudly reports that really important passwords should be unique anyway and written down on paper.
This scheme has more exceptions than rules, it seems, and it doesn't keep its promise it seems to have at first glance.
My scheme
- Generate the strongest password the site allows using an appropriate program.
- Store these passwords in a strongly encrypted password database such as
KeepassKeepassXC.
- Save web-related passwords in the cloud to synchronize them across browsers using a strongly encrypted cloud service such as
LastEnPass.
- Choose very strong passwords for your database and memorize them (and only them).
- Store your database redundantly. Use cloud storage services such as
WualanextCloud offering client-side encryption.
I know what you think. OMGOMG PASSWORD SAFES WHAT ABOUT TROJANS AND KEYLOGGERS AND EEEVEN WORSE!!! OMGWTF IN THE CLOUD IS THIS GUY NUTS!!!
Many users of Windows react in that way. It's a Pavlov's reflex: the deeply internalized belief that infections with malware are inevitable and must be quietly accepted. The argument itself, of course, is not a rational one.
Why not? Well, the argument is that a trojan and an associated keylogger could snatch the entire password database once you enter the master password. Well ... sure they could. And if you wouldn't use a password manager, what do you imagine these keyloggers would do? Delete themselves, being bitterly disappointed?
Try to be strong: they'd collect your passwords, you know, one by one.