Geek [giːk]: A person discovering the cloud the day the icloud is announced.
Nerd [nɜːd]: A person bored to death by geeks chattering about the cloud.
Freak [fɹi:k]: A person believing that clouds are in the sky.
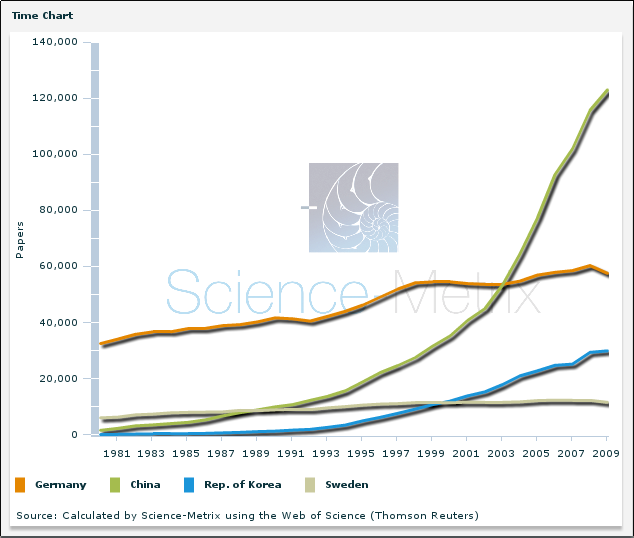
Synchronization of my data has been an issue for me long before Dropbox materialized in 2008. I used a crude but simple solution based on rsync scripts started manually or via the crontab. Something more elegant and efficient would have been possible with inotify as described here. Lsyncd is another option aiming at the same purpose. However, building an automatic two-way sync service based on these tools comparable to Dropbox or Ubuntu One is far from trivial. Since the amount of data I have to sync is steadily increasing, I start to feel a little frustrated with this situation.
As much as I disapprove of the recent hype of cloud services, I cannot deny that Dropbox & Co. are far more complete synchronization services than the primitive and rudimentary solutions I've been using. Particularly, the real-time synchronization offered by these services results in a data integrity unattainable by conventional sync or even backup schemes. For example, while I'm typing this very blog entry, any one of these services would ensure that not a word would be lost even if my cat suddenly hits the power button, because everything I type would be synced in real time to the cloud.
Well, then, why don't I use these services if they are so great? For reasons of control, security, and privacy. As a general rule, I prefer to have control over my data rather than turning them over to an organization which I do not trust by default (and why should I?). This attitude is corroborated by experience, and indeed, there was never a better example than Dropbox. How can we be expected to trust the system if its proven to be broken by design after one critical glance (see also here and here). These security concerns compromise the usability of Dropbox: I really don't want to have to think about which data would better be contained in an encfs encypted folder before putting them on the cloud.
Wouldn't it be great if there were a free and trustworthy service capable of the same effortless, instantaneous synchronization of data as offered by Dropbox & Co? Ideally, this service could be installed on our own servers, so that there'd be no need to register or pay, no size limit, and no one to trust except ourselves. Meet sparkleshare.

Server
Any machine running openssh-server and git-core will do. On pdes-net.org, piet took care of the latter dependency some days ago—thx, piet! 😊
After installation, issuing
cd
git init --bare sync.git
will initialize a git repository in the directory /home/user/sync.git.
For matured versions of git, do the following:
mkdir sync.git
cd sync.git
git --bare init-db
Client
I assume that you have already a public-key ssh connection to the server of your choice. If you connect to server.org via a non-standard port, for example 1234, define it in ~/.ssh/config:
Host server.org
Port 1234
Now, install Sparkleshare and its dependencies. Both Archlinux and Ubuntu had the latest version in their repositories, but YMMV.
If you did not use git before, introduce yourself:
git config --global user.name "Firstname Lastname"
git config --global user.email "first.last@email.com"
Now, start Sparkleshare from the menu or via the commandline by issuing 'sparkleshare start'. Answer the questions. Note that the server address should be in the form "user@server" and the subsequent path should be absolute.
That's it. You have established your own personal cloud. 😊