I haven't talked about backups since more than two years, but as detailed in my previous post, I was recently most emphatically reminded that it isn't clear to most people that their data can vanish anytime. Anytime? Anytime. 
I've detailed what I expect from a backup solution and what I've used over the years in several previous posts (see one, two, and three) and do not need to repeat that here. My current backup scheme is based on borg with support from rsync and ownCloud. The following chart (which looks way more complicated than it is) visualizes this scheme and is explained below.
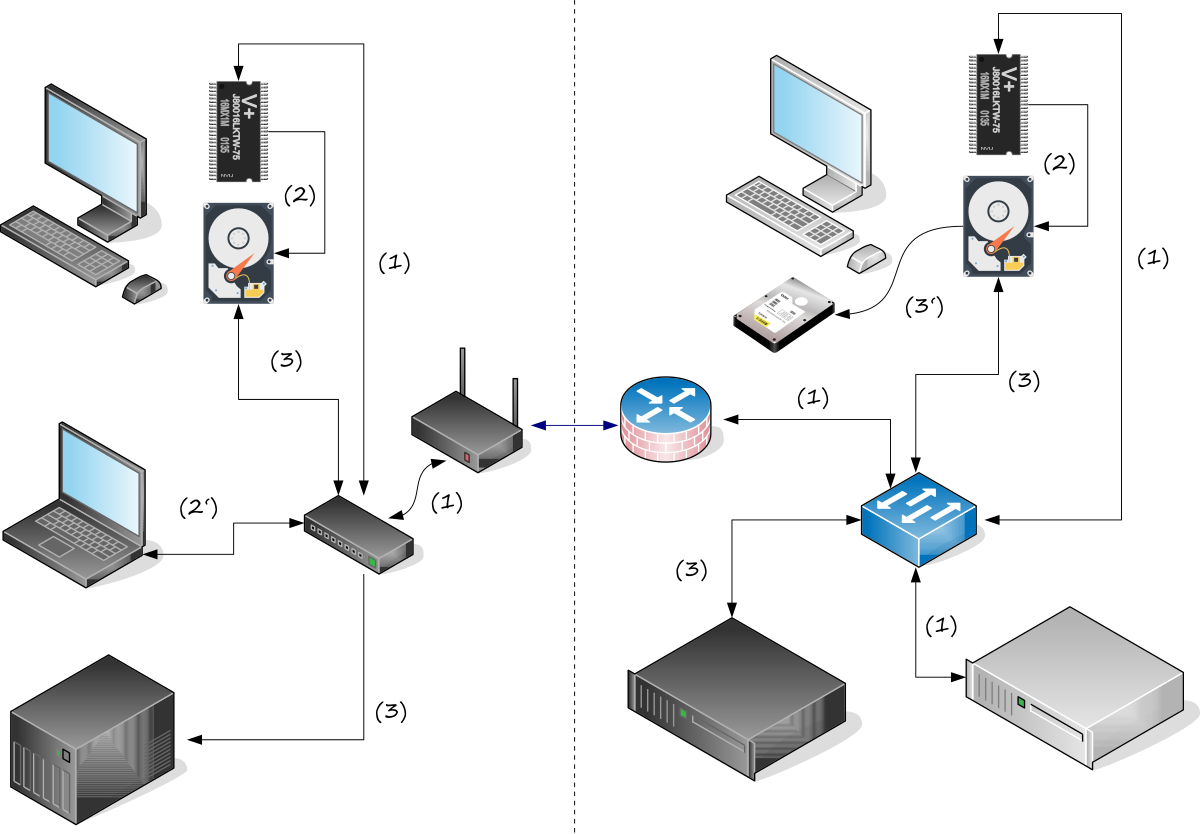
My home installation is on the left, separated from my office setup on the right by the dashed line in the center. The desktops (top) are equipped with an SSD containing the system and home partitions as well as an HDD for archiving, backup, and caching purposes. Active projects are stored in a dedicated ownCloud folder and synchronized between all clients, including my notebooks. The synchronization is done via the ownCloud server (the light gray box at the lower right) and is denoted by (1) in the chart. The server keeps a number of previous versions of each file, and in case a file is deleted, the latest version is kept, providing a kind of poor man's backup. But I'm using ownCloud to sync my active projects between my machines, not for its backup features.
The actual backup from the SSD to the HDD is denoted by (2) or by (2') for my notebooks (to the same HDD, but over WiFi), and is done by borg. The backup is then transferred to a NAS (the gray boxes at the bottom) by simple rsync scripts indicated by (3). All of that is orchestrated with the help of a few crontab entries – here's the one for my office system as an example:
$ crontab -l
15 7-21 * * * $HOME/bin/backup.borg
30 21 * * * source $HOME/.keychain/${HOSTNAME}-sh; $HOME/bin/sync.backup
30 23 * * * $HOME/bin/sync.vms
30 02 * * * $HOME/bin/sync.archive
The first entry invokes my borg backup script (see below) every hour between 7:15 and 21:15 (I'm highly unlikely to work outside of this time interval). The second entry (see also below) takes care of transferring the entire backup folder on the HDD 15 min after the last backup to the NAS. Since my rsync script invokes ssh for transport, I use keychain to inform cron about the current values of the environment variables SSH_AUTH_SOCK and SSH_AGENT_PID. The third entry induces the transfer of any changed virtual machine to the internal HDD. And finally, the fourth entry syncs the archive on the internal HDD to an external one (3'). I do that since once a project is finished, the corresponding folder is moved out of the ownCloud folder to the archive, effectively taking it out from the daily backup. This way, the size of my ownCloud folder never increased beyond 3.5 GB over the past five years. Since the projects typically don't change anymore once they are in the archive, this step effectively just creates a copy of the archive folder.
What's not shown in the chart above: there's a final backup level involving the NAS. At home I do that manually (and thus much too infrequently) by rsyncing the NAS content to the HDDs I've collected over the years. ` 😉 At the office, the NAS is backed up to tape every night automatically. The tapes are part of a tape library located in a different building (unfortunately, too close to survive a nuclear strike 😉 ), and are kept ten years as legally required.
What does all of that mean when I prepare an important document such as a publication or a patent? Well, let's count. It doesn't matter where I start working: since the document is in my ownCloud folder, it is soon present on five different disks (two desktops and notebooks, and the ownCloud server). The backup and sync adds four more disks, and the final backup of the NAS results in two more copies (one on disk, one on tape). Altogether, within one day, my important document is automatically duplicated to ten different storage media (disks or tape) in three different locations. And when I continue working on this document the next days, my borg configuration (see below) keeps previous copies up to six month in the past (see cron mail below).
You're probably thinking that I'm a complete paranoid. 10 different storage media in 3 different locations! Crazy! Well, the way I do it, I get this kind of redundancy and the associated peace of mind for free. See for yourself:
(1) ownCloud
My employee runs an ownCloud server. I just need to install the client on all of my desktops and notebooks. If you are not as lucky: there are very affordable ownCloud or nextCloud (recommended) servers available in the interwebs.
(2) backup.borg
A simple shell script:
#!/bin/bash
#`https://github.com/borgbackup/borg <https://github.com/borgbackup/borg>`_
#`https://borgbackup.readthedocs.io/en/stable/index.html <https://borgbackup.readthedocs.io/en/stable/index.html>`_
ionice -c3 -p$$
repository="/bam/backup/attic" # directory backing up to
excludelist="/home/ob/bin/exclude_from_attic.txt"
hostname=$(echo $HOSTNAME)
notify-send "Starting backup"
borg create --info --stats --compression lz4 \
$repository::$hostname-`date +%Y-%m-%d--%H:%M:%S` \
/home/ob \
--exclude-from $excludelist \
--exclude-caches
notify-send "Backup complete"
borg prune --info $repository --keep-within=1d --keep-daily=7 --keep-weekly=4 --keep-monthly=6
borg list $repository
(3) sync.backup
A simple shell script:
#!/bin/bash
# `http://everythinglinux.org/rsync/ <http://everythinglinux.org/rsync/>`_
# `http://troy.jdmz.net/rsync/index.html <http://troy.jdmz.net/rsync/index.html>`_
ionice -c3 -p$$
RHOST=nas4711
BUSPATH=/bam/backup/attic
BUDPATH=/home/users/brandt/backup
nice -n +10 rsync -az -e 'ssh -l brandt' --stats --delete $BUSPATH $RHOST:$BUDPATH
The two other scripts in the crontab listing above are entirely analogous to the one above.
That's all. It's just these scripts and the associated crontab entries above, nothing more. And since (2) and (3) are managed by cron, I'm informed about the status of my backup every time one is performed. The list of entries you see in the mail below are the individual backups I could roll back to, or just copy individual files from after mounting the whole caboodle with 'borg mount -v /bam/backup/attic /bam/attic_mnt/' (see the screenshot below). You see how these backups are organized: hourly for the last 24h, daily for the last week, weekly for the past month, and monthly for the five months after.
From: "(Cron Daemon)" <ob@pdi282>
Subject: Cron <ob@pdi282> $HOME/bin/backup.borg
------------------------------------------------------------------------------
Archive name: pdi282-2018-12-21--14:15:01
Archive fingerprint: d31db1cd8223ca084cc367deb62e440bfe2dfe4fd163aefc6b6294935f1877b8
Time (start): Fri, 2018-12-21 14:15:01
Time (end): Fri, 2018-12-21 14:15:21
Duration: 19.52 seconds
Number of files: 173314
Utilization of max. archive size: 0%
------------------------------------------------------------------------------
Original size Compressed size Deduplicated size
This archive: 30.14 GB 22.17 GB 1.40 MB
All archives: 975.54 GB 715.02 GB 43.41 GB
Unique chunks Total chunks
Chunk index: 216890 6892358
------------------------------------------------------------------------------
pdi282-2018-06-30--21:15:01 Sat, 2018-06-30 21:15:01 [113186c574898837d0fb11e6fb7b71f62b0a5422d71b627662aec0d2d6a0e0bf]
pdi282-2018-07-31--21:15:01 Tue, 2018-07-31 21:15:01 [8af0cccbab5645490fcec5e88576dad1a3fbbfd3d726a35e17851d7bec545958]
pdi282-2018-08-31--21:15:01 Fri, 2018-08-31 21:15:01 [2d763ea253d18222015d124c48826425e75b83efedeedcc11b24cf8f0d7e8899]
pdi282-2018-09-30--21:15:01 Sun, 2018-09-30 21:15:01 [39932a0d8c081bc05f9cdff54637e3962fd9e622edce8ef64160e79ae767541f]
pdi282-2018-10-31--21:15:01 Wed, 2018-10-31 21:15:02 [49386980b5270554c6c92b8397809736dea5d07c7ccb3861187a6ed5065ba7a6]
pdi282-2018-11-18--21:15:01 Sun, 2018-11-18 21:15:02 [c2eb215ce883fa5a0800a9d4b9a6c53ac82ace48151180e6a15e944dbf65e009]
pdi282-2018-11-25--21:15:01 Sun, 2018-11-25 21:15:01 [e99c2f3baed4a863b08551605eb8ebeaa5ed6a02decccdb88268c89a9b9b9cc0]
pdi282-2018-11-30--21:15:01 Fri, 2018-11-30 21:15:01 [882f6466adcbc43d7e1a12df5f38ecc9b257a436143b00711aa37e16a4dbf54d]
pdi282-2018-12-02--21:15:02 Sun, 2018-12-02 21:15:02 [7436da61af62faf21ca3f6aeb38f536ec5f1a4241e2d17c9f67271c3ba76c188]
pdi282-2018-12-09--21:15:01 Sun, 2018-12-09 21:15:02 [82e6c845601c1a12266b0b675dfeaee44cd4ab6f33dafa981f901a3e84567bbb]
pdi282-2018-12-13--21:15:01 Thu, 2018-12-13 21:15:01 [9ac3dfd4aca2e56df8927c7bc676cd476ea249f4dd2c1c39fc2a4997e0ada896]
pdi282-2018-12-14--21:15:02 Fri, 2018-12-14 21:15:02 [c8c1358f58dae6eb28bd66e9b49c7cfe237720de21214ebd99cc4b4964ec9249]
pdi282-2018-12-15--21:15:01 Sat, 2018-12-15 21:15:01 [e24d3b26dcdf81d0b0899085fb992c7a7d33d16671fba7a2c9ef1215bd3ae8fb]
pdi282-2018-12-16--21:15:01 Sun, 2018-12-16 21:15:01 [27a8a6943f1053d106ced8d40848eccbfb6c145d80d5e2a9e92f891ed98778ce]
pdi282-2018-12-17--21:15:02 Mon, 2018-12-17 21:15:02 [14118ea958387e0a606e9f627182e521b92b4e2c2dd9fb5387660b84a08971a6]
pdi282-2018-12-18--21:15:01 Tue, 2018-12-18 21:15:01 [842c3f7e301de89944d8edf7483956aff2b7cf9e15b64b327f476464825bd250]
pdi282-2018-12-19--21:15:01 Wed, 2018-12-19 21:15:01 [b7f99c56a8e6ee14559b3eddec04646c8a756515765db562c35b8fbefcd4e58e]
pdi282-2018-12-20--15:15:01 Thu, 2018-12-20 15:15:01 [e832afd41762a69cb8c5fe1c14395dde313dc4368871fd27073fdc50e9f7c6c9]
pdi282-2018-12-20--16:15:01 Thu, 2018-12-20 16:15:01 [8471ccb87d513604d31320ff91c2e0aaf0d31e5ff908ff41b8653c55ee11c1e5]
pdi282-2018-12-20--17:15:01 Thu, 2018-12-20 17:15:01 [73a3ae72815a10732fc495317a7e0f8cd9d05eb2ea862f8c01b437138ac82103]
pdi282-2018-12-20--18:15:01 Thu, 2018-12-20 18:15:01 [7eced8e18b52d00300c8f1b17e188fbfc1124dc60adf68ef2924425677615a96]
pdi282-2018-12-20--19:15:01 Thu, 2018-12-20 19:15:01 [6b7dbc4095b704209921424a52ed37d854b3a61c49cc65ac6889d215aad95a6f]
pdi282-2018-12-20--20:15:01 Thu, 2018-12-20 20:15:01 [66da0f57d6c93b149a9fdf679acf5e43fc22ce6b582db4da3ab606df741bdf82]
pdi282-2018-12-20--21:15:01 Thu, 2018-12-20 21:15:01 [1fce9aa4751be905a45ccce7fca3d44be3cf580d5e4b7c4f5091167099df57ad]
pdi282-2018-12-21--07:15:01 Fri, 2018-12-21 07:15:02 [ee551653a18d400719f9ffe1a67787326f5d5dad41be7d7b5482d5610ed86d43]
pdi282-2018-12-21--08:15:01 Fri, 2018-12-21 08:15:01 [264d7ce1dab3bc1578b521a170ee944598fa99f894d6ca273793ad14824b1689]
pdi282-2018-12-21--09:15:01 Fri, 2018-12-21 09:15:01 [b37de3616438e83c7184af57080690db3a76de521e77fd1ae6e90262f6beb1cc]
pdi282-2018-12-21--10:15:01 Fri, 2018-12-21 10:15:01 [6862d0136b2e4ac7fc0544eb74c0085e7baceca7147bd59b13cd68cbf00cb089]
pdi282-2018-12-21--11:15:01 Fri, 2018-12-21 11:15:01 [e5c6ee4ea65d6dacb34badb850353da87f9d5c19bb42e4fb3b951efecd58e64f]
pdi282-2018-12-21--12:15:01 Fri, 2018-12-21 12:15:01 [5b93f864b9422ed953c1aabb5b1b98ce9ae04fe2f584c05e91b87213082e2ff0]
pdi282-2018-12-21--13:15:01 Fri, 2018-12-21 13:15:01 [461f976422c45a7d10d38d1db097abd30a4885181ec7ea2086d05f0afd9169eb]
pdi282-2018-12-21--14:15:01 Fri, 2018-12-21 14:15:01 [d31db1cd8223ca084cc367deb62e440bfe2dfe4fd163aefc6b6294935f1877b8]
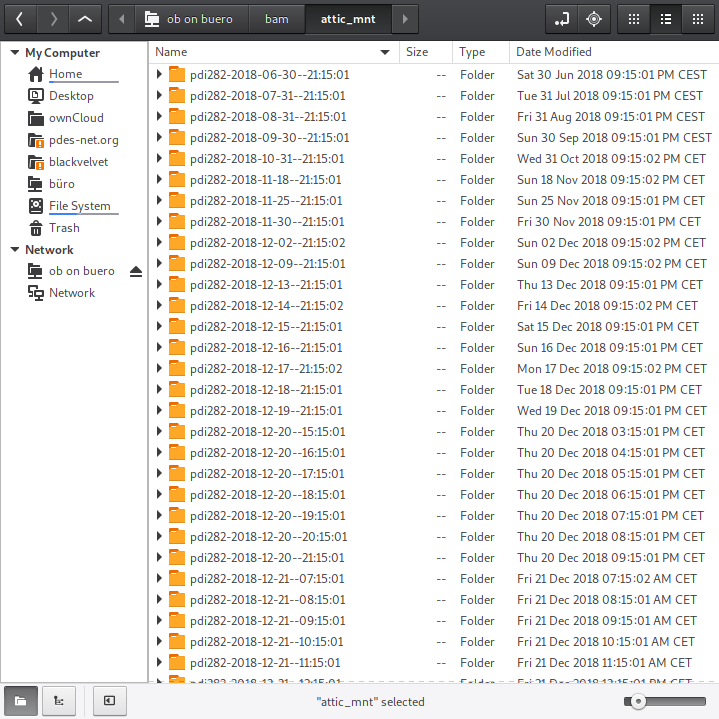
Here's a screenshot of nemo running on my notebook with an sftp connection to my office desktop, after having mounted the available backups with the command given above.




{kind=link}
{kind=link}
{kind=link}
{kind=link}