Maximum spamicity
Now look at this mess:
cd ~/.Mail/Ham/cur grep -ih "spamicity=" * | awk '{printf "%s\n", $4}' | cut -c11-15 | sort | tail -n 1 0.835 cd ~/.Mail/FalseNeg/cur grep -ih "spamicity=" * | awk '{printf "%s\n", $4}' | cut -c11-15 | sort | tail -n 1 0.659
Eieieieieiei ... thats all wrong! Dammit. 😞 What can you do with that? Nothing, nothing at all. *sniff*
Update: All right then, let's pretend I'm an Erklärbär.
{kind=link}
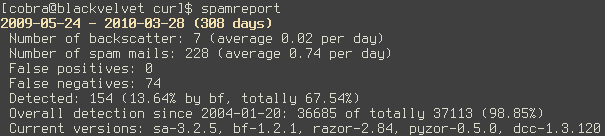
The spamreport conveys a clear message: while the number of spams I receive drops steadily and is now well below one per day, the recognition rate continues to decrease as well and is now at an inacceptable 67%. I've described the reasons for this development previously.
Apparently, the spamfilters of my mail providers are pretty good, and my own, local ones have only limited success in filtering the mails which have escaped the attention of the providers' filters. Bogofilter seems to struggle particularly hard: it contributes only 15% to the overall detection.
Being of the impatient type, I thought I could instantaneously improve the situation by decreasing the threshold of the spamicity with which a particular mail is classified as being spam. Right now, this threshold is set to 0.9.
In fact, the average spamicity as determined by the perl script spamstat (written, as usual, by haui) encouraged that idea: the average spamicity in one of my ham folders is 0.062, i.e., close to zero, while the one in the falseneg folder (where all spam messages end up which were not detected either by bogofilter or spamassassin) is significantly higher: 0.421. So, why not simply set the threshold to 0.4?
Well, because the only thing worse than false negatives are false positives. 😉 I haven't experienced any of the latter in more than two years, and I want to keep it that way. To avoid false positives, however, the maximum spamicity in my ham folders is more relevant than the average one.
It's not difficult to find this value. Here's how:
We first grep for the keyword "spamicity" in all messages. The switch -i ignores the case (capital or not), -h suppresses output of the file name. The result of this first command is a long list of lines which all look like that:
X-Bogosity: Ham, tests=bogofilter, spamicity=0.000000, version=1.1.7
The result is piped to awk, which just prints the fourth column of that line, i.e.,
spamicity=0.000000
This result in turn is piped to cut for selecting the 11th to 15th character, leaving
0.000
The resulting list of numbers with three decimal places is sorted in ascending order, and finally piped to tail to show the very last entry: the maximum spamicity. 😊
The unfortunate result I've obtained of course means that I can forget my original idea of simply decreasing the threshold. Instead I have to let my filters learn, a process requiring great patience.
Just for completeness, and since I've started with all this explaining, let me show you how to train both bogofilter and spamassassin by two example scripts:
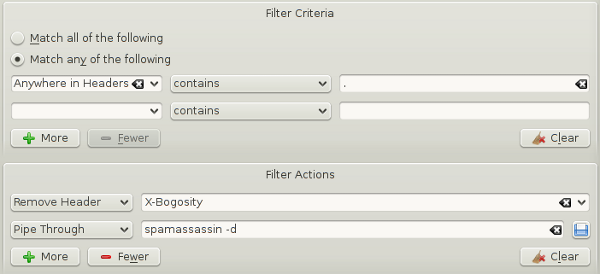
Before running these scripts, don't forget to remove the markup from the mails included in the learning! That's easily accomplished by a custom filter in your e-mail client (here kmail):